Artificial neural networks were developed in the 1950s, but their use in image recognition did not really begin until the late 1980s.
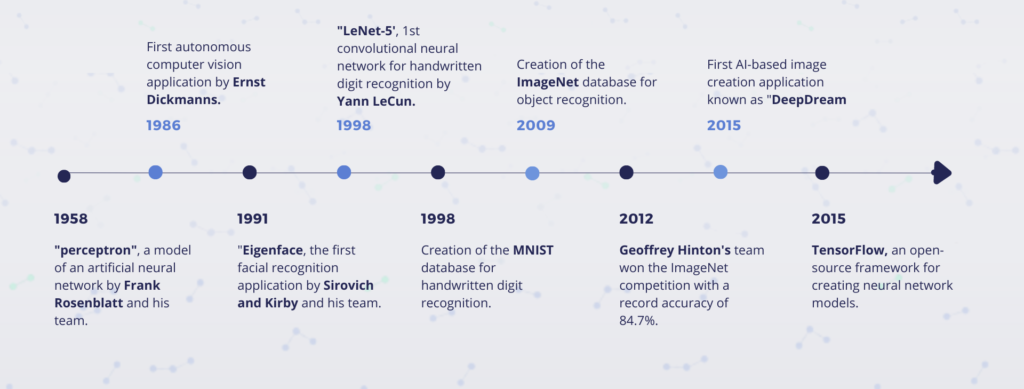
1958: Electronic engineer Frank Rosenblatt develops the first “perceptron”, a model of an artificial neural network
1986: Ernst Dickmanns and his team at the Bundeswehr University Munich in Germany developed the first autonomous computer vision application. They developed a computer vision system to enable a car to drive autonomously. The system used video cameras to capture images of the road and image processing algorithms to identify obstacles and calculate the optimal trajectory for the car.
1991: The first facial recognition application is called “Eigenface” and was developed in 1991 by Sirovich and Kirby and used by Matthew Turk and Alex Pentland for face classification. However, this was a face recognition application based on principal component analysis techniques rather than the neural networks used today.
1998: Yann LeCun and his colleagues at New York University develop LeNet-5, a convolutional neural network model for handwritten digit recognition.
Yann LeCun developed convolutional neural networks (ConvNets) to recognise handwritten numbers on cheques for the AT&T Bell Labs research department. In the 1990s, image recognition with ConvNets stagnated due to the lack of training data and the limited computing power of computers at the time.
1998: Creation of the MNIST database for handwritten digit recognition
2009: Creation of the ImageNet database for object recognition.
These databases allowed researchers to collect and annotate large numbers of images, enabling more complex neural networks to be trained.
2012: Geoffrey Hinton’s research team at the University of Toronto uses a neural network architecture called the Deep Convolutional Neural Network (DCNN) to win the ImageNet competition with a record accuracy of 84.7%.
This victory marked the beginning of a new era for image recognition, where neural networks began to outperform conventional algorithms in many computer vision tasks.
2015: Google introduces TensorFlow, an open-source framework for creating neural network models, which will make it easier to train and use neural network models.
2015 : The first AI image creation application known as “DeepDream” was developed by Alexander Mordvintsev in 2015 at Google. DeepDream uses convolutional neural networks to generate original images from a given source image.